
I'm Umair
A


As a dedicated student pursuing a dual major in Computer Science and Statistics, I bring a passion for the intersection of technology and data analysis to my academic journey. With a keen interest in machine learning, I am driven to explore the intricacies of data science and its applications. My coursework has equipped me with a strong foundation in programming, statistical modeling, and algorithmic problem-solving. Eager to contribute my skills and knowledge to real-world challenges, I am actively seeking opportunities to apply my expertise in machine learning and data analysis in practical settings.

In response to a pressing challenge faced by the up-and-coming startup, Mhapy, my team and I embarked on a collaborative venture to address a critical issue in the realm of mental health. Mhapy possessed a wealth of user data but lacked a convenient means of harnessing it to provide users with valuable insights into their communication patterns and overall emotional tone. Recognizing the significance of this predicament, our project aimed to bridge this gap by developing a practical solution. Leading a team of six, we set out to create an API that effectively utilized the data gleaned from the Mhapy app. My jobs were to manage the group’s priorities, being a product manager, and helping create the LSTM model. Our primary goal was to empower users with a tool that could analyze their text expressions, distinguishing between positive and negative sentiments. The resultant API, seamlessly integrated with Node.js and Flask, not only facilitated sentiment analysis but also presented users with graphical representations of their emotional tone over time. Leveraging cutting-edge technologies such as TensorFlow, PostgreSQL, AWS EC2, and S3 bucket, we ensured the robust hosting of the model. The project's distinctive feature lies in real-time notifications that alert users to instances of heightened negativity, fostering self-awareness and making strides towards a more accessible and user-centric approach to mental health therapy. This initiative reflects my leadership skills and technical proficiency in delivering pragmatic solutions to real-world challenges, particularly at the intersection of AI and mental health. Due to company privacy the code and related work cannot be shared.
In one of my recent projects, I took on the intricate task of developing a machine learning model tailored for educational diagnostics. The primary objective was to predict whether a specific student would answer a given diagnostic question correctly. However, the project came with its set of challenges, most notably the sparse nature of the available data. To navigate this complexity, I delved into a variety of machine learning models, including KNN, item response theory, SVD, and matrix factorization. It became apparent early on that no single model could fully address the nuances of the problem. Consequently, I sought to leverage the strengths of each by experimenting with an ensemble approach, combining KNN, item response theory, and matrix factorization. Acknowledging the room for improvement, I took the initiative to create a custom implementation of matrix factorization. This process involved a thoughtful analysis of the shortcomings observed in earlier models, allowing for a more tailored and nuanced solution. Rather than a showcase of achievements, this project served as a valuable learning experience, emphasizing adaptability and problem-solving. Looking forward, my aim is not just to conclude the project but to continue its evolution. I'm particularly intrigued by the potential enhancements that could come from applying a Bayesian item response theory model. This reflects my commitment to ongoing exploration and refinement, driven by a genuine interest in improving the predictive capabilities of machine learning models in the context of educational diagnostics. The mathematical analysis can be found here.

This project intended to determine whether COVID-19 helped improve air quality in some major cities. This analysis was done in Python using Plotly and Pandas. This project required combining multiple CSV files and cleaning them to make them usable with pandas. I looked for air quality statistics both before and after covid to compare them to each other. Since the data we had was not in the form of standard AQHI (Air Quality Health Index) we had to convert the data given into AQHI before performing any analysis. After doing so we plotted the graphs of both the AQHI before and after COVID to conclude. The full report can be found here.

In this project, we worked with a dataset that contains user searches on the Expedia website. The analysis was completed using R and Jupyter Notebook. Here I aimed to answer three main questions using both hypothesis tests and linear regression. The subset of searches I was interested in were search queries likely made by couples. That is, searches looking for places that would accommodate two people. To do this, I had to clean the data by filtering out searches not made by couples and create new variables from the data to help answer the questions. The first question was whether search queries from this group had an equal number of price-reduced listings as regular-priced listings. The second question was whether people looking to stay longer received higher-rated listings than people looking to stay for a shorter time. Finally, the last question was whether there was a linear correlation between the stars a listing had and the number of reviews. We concluded that the number of price-reduced listings was not a 50/50 split. Additionally, people looking to stay longer were recommended higher-rated places. Finally, the more stars a listing had it seemed to increase the number of reviews on the listing. A comprehensive analysis can be found here.
In this project, I aim to recreate the game brick breaker using the MIPS Assembly language. This was done by manipulating registers and assuming the ball can only move in 4 directions. Some additional features added to the game were: it is played by 2 players, there are sound effects, a time limit, three lives, and a retry option. This project helped provide insight into memory manipulation and the importance of data-first design. The repository can be found here.

For this project, I worked in a large group to create the famous board game Scrabble using Java. This project helped me develop a lot of my GitHub and software design skills. In terms of Github, my group adopted a "develop" workflow. Meaning once we got a working product, we would branch off of develop to accumulate changes and make a pull request to main only after thoroughly testing within the develop branch. Doing this helped keep our main branch working and prevented situations where the game was unplayable. Moreover, we followed SOLID design principles and clean architecture to ensure the code was modifiable and expandable. We went through most of the software development lifecycle to make this project come to fruition. I led the team in managing deadlines and arranging meeting times to ensure we would have a complete product by the due date. The repository can be found here.

In this project, we intended to train a machine learning model on sports tweets to give it the ability to determine the sport a given tweet is discussing. This was done using Twitter’s API to scrape sports-related tweets into a JSON file. We then created a new field stating the sport the tweet is actually discussing. After, the large JSON file was slimmed down and converted into a CSV with only two columns, tweet content and sport. After converting the JSON to CSV, I performed many cleaning techniques to make the data more homogenous. Finally, we cross-validated multiple machine learning models to determine the most successful for our use case. From our analysis, it was discovered that random forest performed the best for our use case and had an accuracy of about 85%. The repository can be viewed here.

In this project, my goal was to train a neural network on Amazon reviews within the video game sector to identify positive and negative reviews. The data set was already available for use and contained reviews from 1996-2014. To achieve my goal, I first split the data into two lists, one for the predictor variable being the review text and one for the criterion variable being either positive or negative. The data set used contained the number of stars given in the review, so I classified positive reviews as those greater than three stars and everything less than or equal to three stars as a negative review. I tokenized the reviews and created sequences ensuring each sequence was the same length by appending 0’s to short reviews and cutting off long reviews. Finally, I trained the neural network and achieved an accuracy of 88%. The repository can be viewed here.
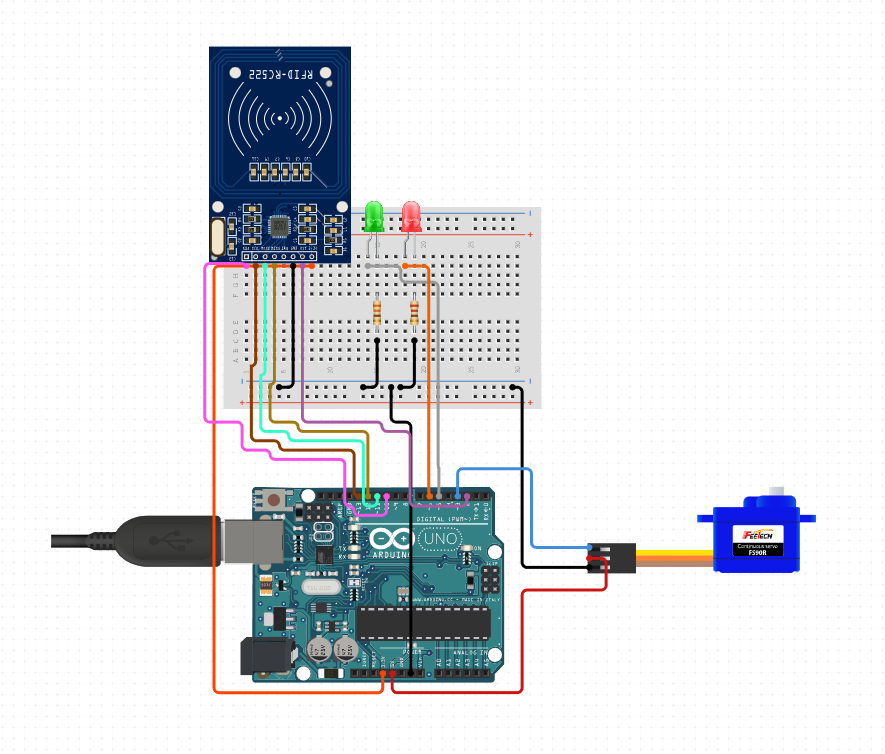
For this project I used an Arduino to create an RFID door lock. Each card has a different ID attached to it, so my program only accepts one sepecific card. When the correct card is scanned the led turns green and the motor turns. However, if an incorrect card is used, the led glows red and the door stays locked. Additional cards can be added after scanning the master card.

In this project, we created a library system using an online server that hosted a PostgreSQL database called ElephantSQL and Java. This allowed us to create a system where all Users interacted with the same database. Our project uses the MVC control pattern to help organize and split up the project. Here we used a database of thousands of books to simulate a library. Then we allowed users to log in and view the books they have checked out and allow them to check out their own books. We also implemented an admin/staff view. This grants access to specific fields not available to regular users. The repository, along with a comprehensive report, can be viewed here.
In this project, I used both Figma and Swift to create a productivity app that would be quick and useful to post-secondary students. The app has three main features the authentication system utilizing Firebase, a to-do list, and a Pomodoro timer. In my experience at school, the issue with other productivity apps was the hassle they caused to create new events. In this app, I strived to be able to quickly create new deadlines without ruining the rhythm of the day. This was achieved using an MVVM architectural pattern to make the project easy to maintain and scale up. Currently, the app has some key functionality, but I plan on continuing to expand it with more features in the future. Here is a demo of the app: